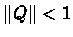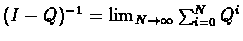Next:
Assumptions
Up:
Notation
Previous:
Expectation of Reward
The discounted value of policy
(where for deterministic policies,
r
d
t
(
s
)=
r
(
s
,
d
t
(
s
)) is the immediate reward for transition from s to
d
t
(
s
))
Theorem 5.1
Let
Q
be a matrix such that
, then
1.
There exists (
I
-
Q
)
-1
2.
(The proof can be found in Puterman's book)
Yishay Mansour
1999-11-24