


Next: Temporal Difference and TD(0)
Up: No Title
Previous: No Title
Another way to look on MC algorithm
In lecture 7 we discussed Monte-Carlo (MC) method for evaluation
policy reward.
This method performs number of experiments and uses the average to
evaluate policy reward.
Another way to express the evaluation is the following:
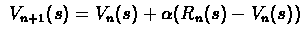
where 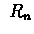 is total reward of n-th run starting first visit in s
(given s was visited in this run).
is total reward of n-th run starting first visit in s
(given s was visited in this run).
Note that
![$\ E[R_{n}(s)] =
V^{\pi}(s) $](img4.gif)
We can rewrite this formula ,as follows,
![$\ V_{n+1}(s) =
(1-\alpha)V_{n}(s) + \alpha[V^{\pi}_{n}(s) + (R_{n}(s) -
V^{\pi}_{n}(s))]$](img5.gif)
where:
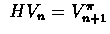 - for some nonlinear operator
H ,and
- for some nonlinear operator
H ,and
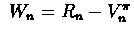 is "noise" and
is "noise" and
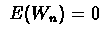 .
.
Recall the operator
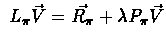 , that was introduced to compute the return of
policy. We've already shown that
, that was introduced to compute the return of
policy. We've already shown that 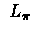 is a contracting
operator.
is a contracting
operator.
Yishay Mansour
2000-01-06