Proximity Search in Databases
Roy Goldman, Narayanan Shivakumar,
Suresh Venkatasubramanian, Hector Garcia-Molina
1998
מוצג ע"י: אייל מישור
הקדמה
מה זה proximity search ?
במה מתאפיין חיפוש כזה ?
מה החידוש במאמר ?
איך עושים את זה ?
דוגמה
Internet Movie Database
(www.imdb.com)
over 140,000 movies
over 500,000 film industry workers
Queries Structure:
Find <keyword> Near <keyword>
דוגמה - המשך

הבעיה
ranking objects in the Find set based on their proximity to objects in the Near set
ה-
framework של הפתרון

IMDB

IMDB

חישוב ה-
proximity
הגדרת ה-bond:

הגדרת ה-score:

מציאת המרחקים
בזמן חיפוש (Dijkstra’s single-source shortest path)
חישוב מקדים (Floyd-Warshall’s all-pairs shortest path)
חישוב מקדים באמצעות Self Joins ........
Self-Joins

Hub Indexing

Constructing Hub Index
נתון H
נבנה את Dist החדשה:

נחשב מרחקים קצרים ב-H ע”י אתחול מ-Dist ושימוש ב-Floyd-Warshall

בחירת ה-
Hubs
נתונה מטריצה בגודל M לשמירת המרחקים בין ה-hub-ים.
בחר שורש M צמתים עם הדרגה הגבוהה ביותר להיות
hub-ים
Performance Experiments
Sun SPARC/Ultra II (2x200 Mhz) running SunOS 5.6, with 256 Mbs RAM, and 18 Gbs local disk space
IMDB - 4MB of 1997 films.
S = 10; no more than 2.5% hubs
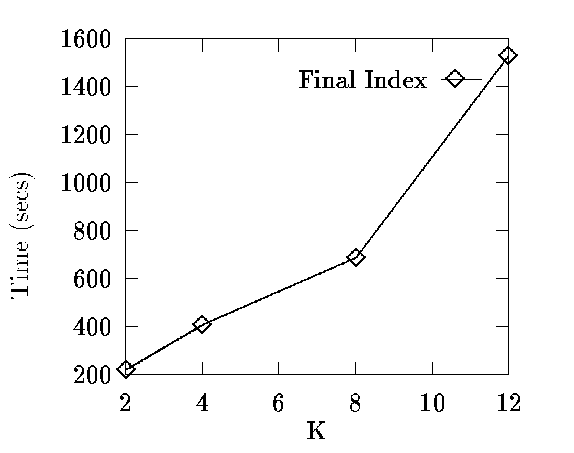
S = 10; no more than 2.5% hubs

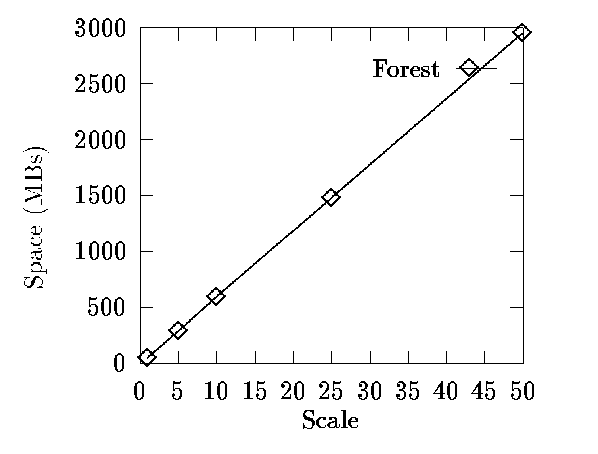
K= 12 no more than 2.5% hubs
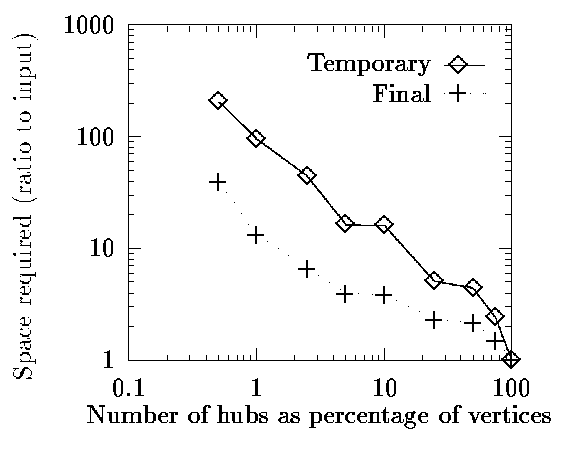
S = 10; K = 12
הרחבות
שיפור השיטה למציאת hubs
תמיכה ב-queries מורכבים יותר (הוספת not, קינון)
הכנסת proximity search ל-SQL
עדכון אינקרמנטלי של האינדקסים כשהנתונים משתנים
שמירת המסלולים הקצרים ולא רק המרחקים.